
Review - Transformer-Based Language Models for Software Vulnerability Detection
Intro
이 논문은 transformer 를 기반으로한 언어 모델을 이용해 소프트웨어에서 취약점을 탐지하는 기법에 대한 전반적인 내용을 정리한 논문이다.
이 논문에서는 다음과 같은 사항을 다룬다.
- transformer 기반의 언어 모델을 이용한 취약점 탐지를 위한 시스템적인 프레임워크
- 기존의 RNN 기반 취약점 탐지 모델에 비한 transformer 모델의 비교적 우위
- transformer 기반 언어모델에 적합한 플랫폼
나는 transformer 입문자이고, 아직 어떻게 NLP 를 이용해 취약점을 탐지하는지 잘 감이 안잡혀서 전반적으로 어떤 방식으로 데이터셋을 준비하고 fine-tunning 을 하는지를 알기 위해 해당 논문을 리뷰하는 것을 채택했다. 따라서 이 관점으로 해당 논문을 리뷰할 생각이다.
Data translation
먼저 모델이 코드를 이해하기 위해선, 코드를 벡터화 하는 절차가 필요하다. 이때 코드를 조각내는 것을 Tokenization 이라고 하고 이를 벡터화 하는 것을 Embedding 이라고 하고, 이 전반적인 과정을 Data translation 이라고 한다.
먼저 Tokenization 을 수행하기 전에 전체 코드를 샘플링하는 것이 필요하다. 예를 들어 입력값을 모든 코드 전체를 넣는 것은 의미가 없기 때문에 라벨링이 가능한 코드 조각을 만들고, 그 코드조각에 라벨을 부여해야 하는데, 이러한 코드 조각들을 Code gadget 이라고한다. 해당 논문에서는 Li 가 제시한 code gadget 생성 방법을 썼다.
해당 방법으로 code gadget 을 생성하고 라벨링을 한 후에 중복된 코드 가젯들을 없애주는 과정이 필요하다. 예컨데 코드 가젯은 자동화 된 방법으로 가져올 텐데, 같은 내용의 동일한 라벨을 가진 중복 코드 가젯이 있다면, 이는 test set 과의 충돌을 야기할 수 있고, 같은 내용의 다른 라벨의 코드 가젯이 있다면, 모델 학습의 성능을 저하시킬 수 있기 때문이다. 해당 논문에서는 코드 가젯을 Hashing 하고, 동일한 내용의 동일한 라벨은 하나만 남기고, 동일한 내용에 다른 라벨의 가젯은 삭제하는 과정을 수행했다.
그 뒤에 이를 Embedding 했는데, 사용하는 모델에 따라 적절하게 맞는 tokenizer 및 Embed 모델을 선별하여 사용했다.
System flow on transformer-based software vuln detection
해당 논문에서는 기존 pre-trained 된 모델을 사용하고, 해당 모델의 head 에 분류기를 추가해 결과를 도출해내는 식으로 전체 시스템을 설계했다.
이때, 각 모델은 pre-trainning 을 하는 시점에 학습을 시키는 방법이 다양하므로 각각 추가하는 레이어를 다르게 설정했다.
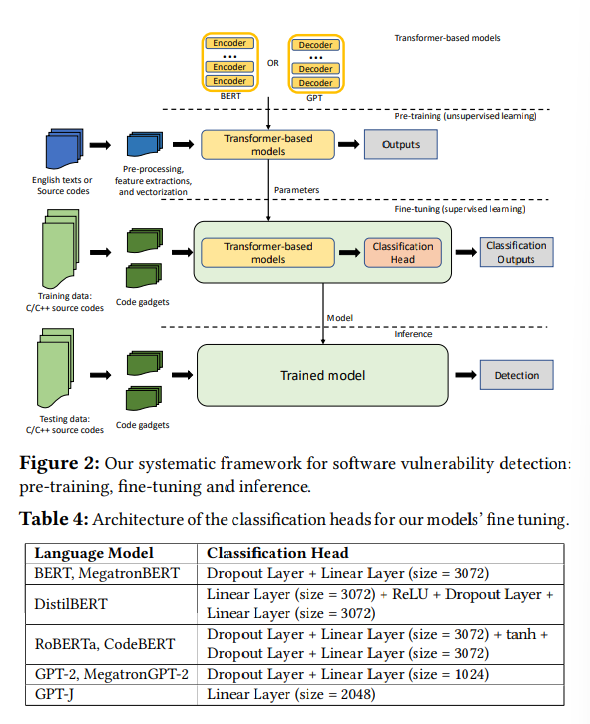
Conclusion
Datatranslation 과정에서 데이터를 준비하는 것이 얼마나 중요한 과정인지 알게 되었지만, 아직 fine-tunning 에서 layer 를 추가하는 방법에 대한 자세한 기술이 없어 고민이 완전히 해결되진 못했다.
표에 나온 Linear Layer 나 Dropout Layer 등을 공부해 볼 필요가 있을 것 같다. 그 내용을 이해하고 논문을 다시 보면 더 도움이 될 것 같다.